
Module I. A et les Arts [visuels]
Une introduction aux usages de l'« IA » dans les domaines artistiques

Anas Ghrab · 5 juillet 2025
Concepts fondamentaux
Applications du machine learning
- Traitement du texte (traduction, analyse de sentiments, génération de texte)
- Reconnaissance d'images et de vidéos (classification, détection d'objets, génération d'images)
- Traitement de la voix et du son (reconnaissance vocale, synthèse vocale, analyse d'émotions, etc.)
- Prédiction et recommandations (moteurs de recommandation, prévisions financières, détection de fraudes…)
- Applications génératives (création d'images, musique, vidéos, texte…)
Les systèmes de recommandation
Algorithmes qui suggèrent des contenus, produits ou contacts pertinents à chaque utilisateur (pertinence souvent mesurée avec les Likes).
- Vidéo & musique : Netflix, YouTube, Spotify
- E-commerce : Amazon, Cdiscount
- Réseaux sociaux : Facebook, Instagram, TikTok, LinkedIn
- Actualités & articles : Google News, Medium
- Voyages & idées : TripAdvisor, Airbnb, Pinterest
L'IA générative
I. LLM (Large Language Models)
Générer du texte / ChatBots
II. Diffusion Models
(Modèles de diffusion)
Dédiés à la génération d'images
II. Modèles multimodaux
(à la fois du l'image et du son)
Mais est-ce que c'est de l'Art ?
- Démocratisation d'un nouvel outil qui peut être utilisé pour la création artistique :
IA = le Deep Learning et ses différentes techniques - Condition : personalisation de l'outil (maîtrise technique / choix et manipulation des paramètres)
- Celui qui décide du résultat final, c'est l'utilisateur, qui présenterait cela comme de l'art ou pas (puis les critiques d'art)
- Qui est l'artiste ? L'utilisateur qui génère ou l'ingénieur qui a conçu le modèle ?
Arts génératifs et IA
- L'art génératif (visuel ou sonore) existe bien avant le Deep Learning
- Art [et technologie] / Art [et ordinateur]
- Art algorithmique (coding)/ procédés aléatoires / probabilistes
Pithoprakta (1955-56)

Les trois ingrédients
de l'IA actuelle
À partir de 2012
(= Deep Learning)
II. Le matériel informatique
=> Les cartes graphiques (GPU)
=> Les cartes graphiques (GPU)
III. La théorie mathématique
=> Les réseaux de neurones
Ordre de grandeur des nombres
| Préfixe SI | Valeur | Échelle pratique | Échelle longue (EU) | Échelle courte (US) |
|---|---|---|---|---|
| kilo (k) | 10³ | mille | mille | mille |
| méga (M) | 10⁶ | million | million | million |
| giga (G) | 10⁹ | milliard | milliard | billion |
| téra (T) | 10¹² | mille milliards | billion | trillion |
| péta (P) | 10¹⁵ | million de milliards | billiard | quadrillion |
| exa (E) | 10¹⁸ | milliard de milliards | trillion | quintillion |
| zetta (Z) | 10²¹ | mille milliards de milliards | trilliard | sextillion |
Bases de Données pour la Génération d'Images/Vidéos
| Nom | Type | Taille | Utilisation | Exemples de Modèles |
|---|---|---|---|---|
| ImageNet | Images | 14M+ | Pré-entraînement, classification | StyleGAN, BigGAN |
| LAION-5B | Image+Texte | 5 milliards | Texte → Image | Stable Diffusion |
| COCO | Images + Annotations | 330K | Segmentation, captioning | DALL·E, Flamingo |
| FFHQ | Visages HQ | 70K | Génération de visages | StyleGAN2 |
| WebVid-2M | Vidéo+Texte | 2.5M | Texte → Vidéo | VideoCrafter, Sora |
| Kinetics-700 | Vidéos | 650K | Reconnaissance d'action | VideoGPT, Make-A-Video |
| CC3M/12M | Image+Texte | 3M / 12M | Captioning, multimodal | DALL·E mini, CLIP |
Erreurs Systémiques
[en génération d'images]
- Biais sociaux : Surreprésentation d'hommes blancs pour les rôles prestigieux (e.g. CEO, docteur).
- Anomalies anatomiques : Mains difformes, visages asymétriques → difficulté à modéliser la cohérence spatiale.
- Biais culturels/géographiques : Images centrées sur l'Occident, objets et styles majoritairement américains/européens/asiatiques (manga, etc.)
- Incohérences sémantiques : Objets impossibles, texte illisible, scènes absurdes (même avec prompts clairs).
- Certaines erreurs → Glich → Forme artistique ?
- Il peut être intéressant d'utiliser des modèles « dépassés » car ils produisent plus d'« erreurs ».
Google DeepDream (2015)
Visualiser les couches intermédiaires d'un modèle CNN, en accentuant l'activation dans certaines couches
Transfert de style (2015)

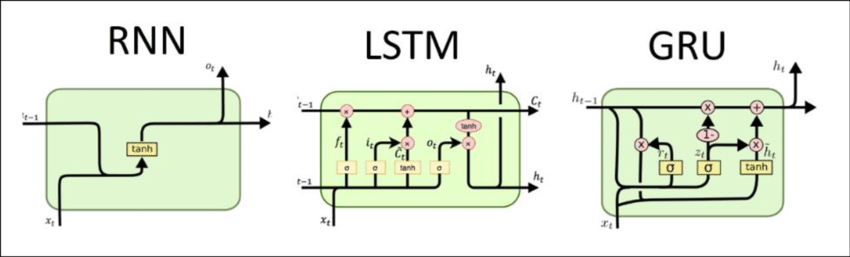
Musique algorithmique => RNN
Juckdeck (2010-2019)

Rachetée en 2019 par TikTok Information Technologies UK Limited.
Magenta (Google Brain, 2016)
- 2013 : Variational Autoencoder (VAE)
- 2018 : MusicVAE (https://magenta.tensorflow.org/music-vae)

MusicTransformer (Magenta, 2018)
- Générer des formes musicales plus cohérentes (relations éloignées entre les sections)
- Apprentissage effectué sur des fichiers MIDIs
- Générer du MIDI (représentation symbolique)

MuseNet (OpenAI, 2019)
https://openai.com/index/musenet/
Génère dans différents genres musicaux

JukeBox (OpenAI, 2020)
https://openai.com/index/jukebox/Jukebox: A Generative Model for Music
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever (https://arxiv.org/abs/2005.00341)
MusicML (Google, 2023)
 https://google-research.github.io/seanet/musiclm/examples/
https://google-research.github.io/seanet/musiclm/examples/
MusicGen (Meta, 2023)

- Modèle de Langage (LM) unique pour la génération musicale conditionnelle
- Fonctionne avec des tokens musicaux compressés, éliminant le besoin de plusieurs modèles
https://huggingface.co/facebook/musicgen-small
Modèles Génératifs :
Open-Source vs Propriétaires
| Modèle | Image ou Musique | Type | Organisation |
|---|---|---|---|
| Stable Diffusion | Image | Open-source | Stability AI |
| DALL·E 3 | Image | Propriétaire | OpenAI |
| Midjourney | Image | Propriétaire | Midjourney Inc. |
| Imagen | Image | Propriétaire (non public) | Google DeepMind |
| Kandinsky 3 | Image | Open-source | Sber AI |
| MusicLM | Musique | Propriétaire | Google DeepMind |
| Riffusion | Musique | Open-source | Indépendant |
| Jukebox | Musique | Open-source | OpenAI |
| Suno (AI Songwriter) | Musique | Propriétaire | Suno.ai |
Éléments de conclusion/réflexion
- Qu'est-ce que l'Art / qu'est-ce que la musique ?
- Un outil nouveau (pinceau / appareil photo / caméscope)
- De nouvelles techniques de création dont il faut saisir les différents enjeux.